Last Friday I needed to work on migrating an older Neo4J project into a new setup currently in development.
As the old website needs to remain online while working on the new I devised some trickery in bypassing the old website and talk to the Neo4J instance directly via a small REST wrapper which would return the data in JSON format. That way I can merge old- and new data in the client and via some reverse proxy magic I can maintain the same URL while in future I can swap the data source around. That way I can get rid of the need of an instant data migration and let the javascript client in the browser do most of the work, hiding the ugliness of different sources in the backend.
Schedule for the day: implement a quick Python script which queries the Neo4J database for one specific set of nodes and dump them into JSON, translating the property names if needed. When done implement the dataview in the new system using the mixed content of the old and new system. Should be doable before the end of the day which would be great as deadlines have been moving into the future forever on this project.
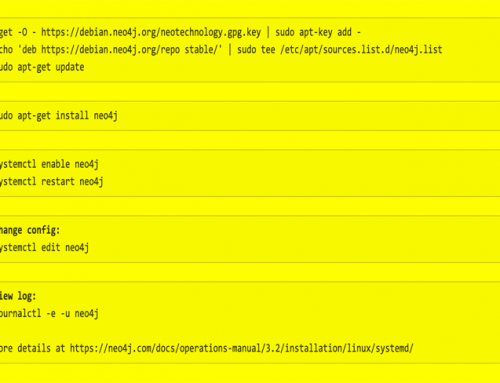
First step: have a glance in the web-interface to see how nodes and properties are named; the Neo4J web-interface on :7474 is great for stuff like that. I always keep it available, either protected via a firewall setting or via an ssh tunnel.
Today however I was greeted by: 503 Service unavailable error served up by Jetty.
Weird; not thinking too much of it I rebooted the VM which had been running for 2oo+ days; the system daily stops the Neo4J instance and makes backups with rsync which are stored on another machine. It being at version 2.3.3 at the time it seemed the best I could do with the community version.
Rebooting a VM is always quick; this time it seemed to have forever for Neo4J to start up. After stopping and starting the service a few times I gave up and tried the console mode. For me it is the best way to see what is going:
“`
Oops that’s bad news.. Several scenario’s flashed through my head. Loosing that data would be “less than ideal”. I quickly made a local VM with the same Neo4J version to run experiments on. One of the scenarios was an early upgrade to the current 3.2 branch but for that I needed to update to 2.3.7 first. Stuff I really did not want to do on the live server without trying somewhere else first.
The friday morning switched into nightmare mode when I found out that the backup of the previous day had the same issues, as had the backup of last week, and that of a month earlier.. Apparently there was some corruption which has been going on for ages.
At this point I reached out to Neo4J hoping that somehow the database could be revived using the corrupted files.
While working on getting https://github.com/jexp/store-utils to work Michael suggested removing the files which were mentioned in the error; the neostore.counts.db.* ones. That did not help on the live server but on the local test one it did work. Turned out that I also removed the transaction logs there `neostore.transaction.db.*`
After making a copy of the corrupted dataset on the live server I removed the transaction files from the live folder and low and behold.. It started again.
I immediately stopped the server again and grabbed another copy of the data; while I had all kind of issues with running the store-utils earlier it happily processed this dataset. Michael also suggested to do a manual consistency check as outlined here at https://neo4j.com/developer/kb/how-do-i-run-consistency-check-manually/ That came through fine as well.
Lessons learned:
- test your backups often
- monitor the output of the backup-script
- upgrade to 3.x for all projects ASAP
- when doing stuff with 2.xx on a clean Ubuntu install; run apt install default-jdk before anything else
Note: since the 3.x series backup-tools are supplied for all versions https://neo4j.com/docs/operations-manual/current/backup/
A special thanks to Rik and Michael @neo4j for their support and assistance!