When migrating data from legacy systems to Neo4J there are various ways to choose from. There is this high-speed specialised import tool /usr/bin/neo4j-import which offline prepares a database from a collection of CSV files. A great help if it fits your problem.
However most of the time I find myself writing scripts to read data from a source, do some conversions on them and then put them in the graph. My default tool to go to in cases like that is the Python language and the excellent py2neo library.
Python has a very rich environment capable of reading almost any file format you can think of and py2neo provides a very reliable connection to the graph. This method is notoriously much slower than the import tool as everything is send via HTTP and the transactional pipe. But with the conversions power of Python at your fingertips it is a very capable way. Often a script becomes a self-contained piece of “magic” which does its conversion magic in a very repeatable way, great when you need to do stuff more than once.
Recently I was working on a project where some “lists” needed to be migrated in the graph. Typically it were lists of 5 to 15 entries resembling some “kind of thing” and used in the frontend to present them in a SELECT or Checkbox kind of interface.
Like a Pavlov dog I started a new Python script to mould 5 lines of CSV into the graph. The first few keystrokes shivered down my spine. Something was silly here. Although I wrote stuff like this numerous times before it felt wrong for doing it this way. 5 lines, no conversions, no magic, make a CREATE statement from it and paste it into the console and be ready. Right?
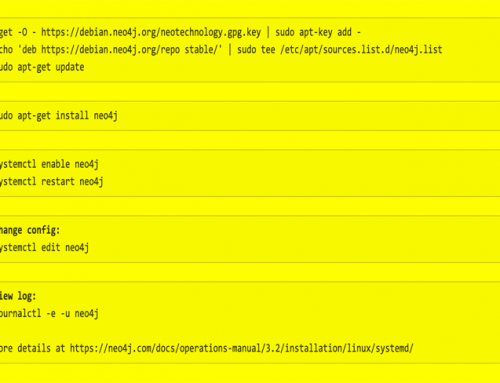
But those commands would get lost in the conversion train I was building to repeat the conversions to create a fresh dataset when needed. Ah but there is a tool for that! Just in time I remembered the existence of /usr/bin/neo4-shell. It can read from a file and I quickly drafted a .cypher file instead of a silly .py :
CREATE (c:Certification) set c.name='ISO 27001';
CREATE (c:Certification) set c.name='ISO 9001';
CREATE (c:Certification) set c.name='ISO 50000';
CREATE (c:Certification) set c.name='ISO 14001';
CREATE (c:Certification) set c.name='NEN 7510';
CREATE (c:Certification) set c.name='OHSAS 18001';
CREATE (c:Certification) set c.name='PCI DSS';
CREATE (c:Certification) set c.name='ISAE 3402';
CREATE (c:Certification) set c.name='SOC 2-2';
CREATE (c:Certification) set c.name='EU Code of Conduct';Boom! Done! I dropped in the Unix shell and typed:
neo4j-shell -file certifications.cyNothing. Zilch. Nada; it just hangs. The neo-shell was trying something which took forever to finish never returning to the commandline. Weird. So forget about that file for a moment and try without any parameters.
neo4j-shell
Great; same thing, just sitting there waiting for the shell which never comes.. The smart thing to do at this moment is to shrug your shoulder and move back to the known route and finish the task. Just create that Python script and be done with it.
But of course I couldn’t; I had to know what was wrong with my beloved database. I knew that shell was working, I played with it before, just not on this VM. I opened a Terminal on my Hackintosh and voila, instantly I was presented a neo4j shell connected to the Neo4J instance running there.
Would it be a VM issue? The development work is done in an Ubuntu VM running on that same Hackintosh to mimic the production environment where the actual site is hosted. Puzzled by “the waiting shell” I decided to run tcpdump to see if anything was going on the network interface.
And there it was (ip removed to protect the innocent):
14:54:20.786685 IP 10.10.10.236.54356 > ec2.eu-central-1.compute.amazonaws.com.38501: Flags [S], seq 585485534, win 29200, options [mss 1460,sackOK,TS val 14512 ecr 0,nop,wscale 7], length 0
14:54:21.783045 IP 10.10.10.236.54356 > ec2.eu-central-1.compute.amazonaws.com.38501: Flags [S], seq 585485534, win 29200, options [mss 1460,sackOK,TS val 14762 ecr 0,nop,wscale 7], length 0
14:54:23.787052 IP 10.10.10.236.54356 > ec2.eu-central-1.compute.amazonaws.com.38501: Flags [S], seq 585485534, win 29200, options [mss 1460,sackOK,TS val 15263 ecr 0,nop,wscale 7], length 0
14:54:27.791060 IP 10.10.10.236.54356 > ec2.eu-central-1.compute.amazonaws.com.38501: Flags [S], seq 585485534, win 29200, options [mss 1460,sackOK,TS val 16264 ecr 0,nop,wscale 7], length 0
The Neo4J-shell is trying to connect to the remote Amazon instance of the real site! After some pondering and experimenting I found the reason: the hostname of this VM was identical to the remote production site. When starting the shell it somehow resolves the local hostname and obviously that gives the real IP; thus it tries to connect to it. Due to the restrictions in the Amazon security groups it can’t but it won’t give up trying. It keeps you waiting on the shell that will never come..
Trying to be smart doesn’t help either; passing it -host localhost or even -host 127.0.0.1 does not help. t prioritises the ip found and ignore the overrides. Stubbornly it keeps trying to connect to the remote site.
The only real solution is to give in and rename the VM to something which correctly resolves to the correct IP of the VM.
All this happened a while ago and I mostly forgot about… Until recently… Those migrations and other work resulted in an update to be performed online. I ssh’d into the Amazon VM and started running them. All was fine until the first neo4j-shell script needed to run.
Nothing, waiting for the shell again.. But why? The hostname was valid but it turns out that it resolves to the external IP of the instance and not the local 172.131.0.0 number which is assigned to the interface locally. Same case here, trying to override it with -host does nothing.
Luckily the solution is simple; add the name of the machine to /etc/hosts in the list of 127.0.0.1 to make it a local name. Then reboot to get rid of cache and get the change live. Apparently in Ubuntu this is the only reliable way to force changes in /etc/hosts. It looks like Unix but it behaves like Windows 😉
Once I’ve done that it works like a charm. But Java, RMI and DNS seem an iffy combination. If you find yourself waiting for the shell that never comes make sure you check your hostname resolves to 127.0.0.1
It would be great if the Neo4J shell would change its behaviour and at least use the IP number specified on the command-line but looking at all the Google results concerning Java RMI and not being a Java programmer myself that might be a holy grail instead of an easy fix..
Knowing how to fix it will do for the time being; at least I am no longer waiting for the bus ^H^H^H shell!